Существуют сотни теорий как правильно делать перелинковку проекта. Понапридумывали разные там «кольца» , «звезды» , «кубы» и прочие методы. Теоретизировать о плюсах и минусах можно много и долго — язык, авось, не отваливается, а бумага стерпит. Ни один из теоретиков вам не скажет — поставь 100 ссылок с такими-то анкорами с таких-то страниц на такую-то и гарантировано обретешь счастье в виде могучего потока трафика. Они лишь будут рассуждать о преимуществах одной схемы перед другой и кичиться теориями, ссылаясь на авторитетов.
Единственным, окончательным, решающим мерилом правильности перелинковки является нахождение в ТОПах поисковых систем. Поэтому мы и будем анализировать лидеров ТОПов.
Для работы нам потребуется Screaming Frog SEO Spider. У меня корпоративная лицензия, а вы можете найти ключ, сами знаете где. Впрочем если анализируемый сайт до 500 страниц, можно пользоваться и триальной версией.
Далее выбираем лидера ТОПа по интересующим ключам и начинаем его препарировать. Наша задача — понять, как устроена перелинковка на его сайте, вычленить все страницы с исходящими внутренними ссылками, понять на какие страницы он ссылается и собрать базу анкоров для внутренней перелинковки. Повторив и расширив его перелинковку на своем проекте, мы сильно продвинемся к вершинам ТОПов.
В качестве пациента возьмем абсолютно любой сайт, ну например по запросу «Как купить дешевые авиабилеты» в Гугле. Получаем в выдаче вот такую красоту

Поскольку я увидел по запросу красивый блок с ответами Гугла, то естественно для препарирования выбираем сайт travelq.ru. Соберем немного информации о нем. Во первых сайтик собран на WordPress, поскольку есть вход в админку по урлу travelq.ru/wp-login.php. Во-вторых, не смотря на отсутствие счетчиков, трафик на нем есть и по Semrush составляет 6,5 тыс (что в уникальных посетителях с Гугла составит 2-2,5 тыс в день):

В-третьих, сайт плотно сидит в верхних позициях по 1,5 тыс запросах

Итак, сайт неплохой, приступаем к препарированию. Спарсим сайт упомянутым Screaming Frog SEO Spider. Вот настройки его конфигурации:

Видим что на сайте 587 страниц и под тысячу других элементов в виде картинок, скриптов и так далее.
Выбираем вкладку Internal и ставим фильтр «Html» :

Чуть ниже мы видим непосредственно все страницы сайта. Теперь разберемся с 2 важными вкладками в нижней части «Inlinks» и «Outlinks». Щелкнем любую страницу в списке:

Как следует из названия, «Inlinks» — все входящие ссылки на страницу, включая ссылки с изображений, ссылки со скриптов, ссылки с CSS и т.д.
«Outlinks» — все исходящие с данной страницы ссылки, включая ссылки с картинок, скриптов и внешние ссылки за пределы сайта.
Теперь у нас все готово для анализа. Мы можем посмотреть ссылки на страницу непосредственно в SEO Frogs, но придется анализировать страницы по отдельности, либо выгрузить все ссылки сайта и провести комплексный анализ ссылочного.
Как найти ссылки от шаблона и меню
Теперь самое главное: нам нужно зачистить ссылочное от шаблона и главного меню. Я имею ввиду сквозное меню и шаблон, ссылки в котором практически не имеют вес из-за их значительного числа. ПС умеют ловко отделять контент от шаблона и мы сейчас повторим это за ними.
Чем характеризуется главное меню? Это анкор + ссылка на определенную страницу. Зачистив весь массив спарсенного с сайта ссылочного от этой пары, мы получим ссылочное из контента + ссылочное от второстепенных меню (которые разные на отдельных страницах и образуют небольшие по численности пары).
Чтобы найти все ссылочное из шаблона, посмотрим какая страница обладает наименьшим числом контента, в том числе и генерируемого динамически. Как правило, это страница контактов, страница о сайте. Найдем страницу контактов travelq.ru/kontaktyi в SEO лягушке и скопируем в Excell данные закладки «Outlinks». Все исходящие с этой страницы мы примем за исходящие из шаблона + главного меню.

Вставляем все значения в Эксель и видим следующую картину:
- В столбце А — тип ссылочного (текстовая, картинка, скрипт)
- В столбце C — на какую страницу ведет ссылка
- В столбце D — анкор ссылки
- В столбце E — alt ссылки-картинки
Теперь сцепляем столбцы С и D формулой

Мы получили массив строк в столбце G, по которым мы будем чистить все ссылки, выгруженные с сайта.
Как зачистить все ссылки сайта от шаблона
В SEO лягушке выгружаем отчет Bulk Export — All Anchor Text. Открываем его в Excell. Мы получили более 35,7 тыс. ссылок. Теперь зачищаем это ссылочное от шаблона. Вставляем подготовленные «сцепленные» строки в виде значения (Правка — специальная вставка — значения), например в столбец K .
Далее повторяем сцепление на выгруженных ссылках столбцов Destination и Anchor в столбце I ( =СЦЕПИТЬ(E2;C2) )и копируем на весь диапазон.
Сейчас мы проверим каждое значение столбца I на данные шаблона из столбца K. Для этого введем в столбце J формулу =ПОИСКПОЗ(I2;$K$2:$K$99;0)
Скопировав формулу вниз на весь диапазон получаем при цифровом значении — ссылка с таким анкором и таким урлом — есть в шаблоне, #Н/Д — отличная от шаблона ссылка, которые нам и нужны.
Делаем автофильтр по всем значениям кроме #Н/Д.

Удаляем их. Снимаем фильтр.
Мы получили ссылочный профиль сайта без учета шаблона. Всего в нем сейчас 18 тыс значений. Эти 18 тыс ссылок как то участвуют в передаче веса и перелинковке. Сейчас мы с Вами проделали то, что делают ПС с каждым сайтом — дешаблонизировали его.
Удаляем все столбцы с формулами, оставляем только столбцы A-H.
Не смотря на наши настройки, у нас спарсились домены 3 уровня (sodyba.travelq.ru, guide.travelq.ru и пр). Они жестко перелинкованы с доменом второго уровня и с одной стороны нужно их, конечно, учитывать в перелинковке самого travelq.ru, а с другой стороны речь не стоит в учебной статье о комплексном анализе.
Проанализировать их просто:
в Столбце B делаем текстовый фильтр не содержит .travelq.ru и тут же
в Столбце C делаем текстовый фильтр содержит .travelq.ru .
Мы видим 65 ссылок, которые ведут с домена 2 уровня на домены 3 уровня со всеми анкорами.
Поменяв содержит и не содержит местами мы увидим ссылки, которые ведут на наш домен 2 уровня.
В ячейку F2 вводим формулу =ЕСЛИ(E2=»»;D2;E2) и копируем ее вниз. Логика формулы такова, если анкор пустой (столбец E), то берем значение из alt (столбец D). Переименовываем этот столбец в Anchor2

Приступаем к анализу
Строим первую сводную таблицу, выделив весь диапазон данных. Для начала смотрим весь анкор лист и откуда и куда идут ссылки.

Мы можем посмотреть данные в разрезе всех входящих анкоров и страниц на конкретную страницу. Давайте посмотрим что именно входит на страницу, из которой Гугл сделал красивый блок с ответами:
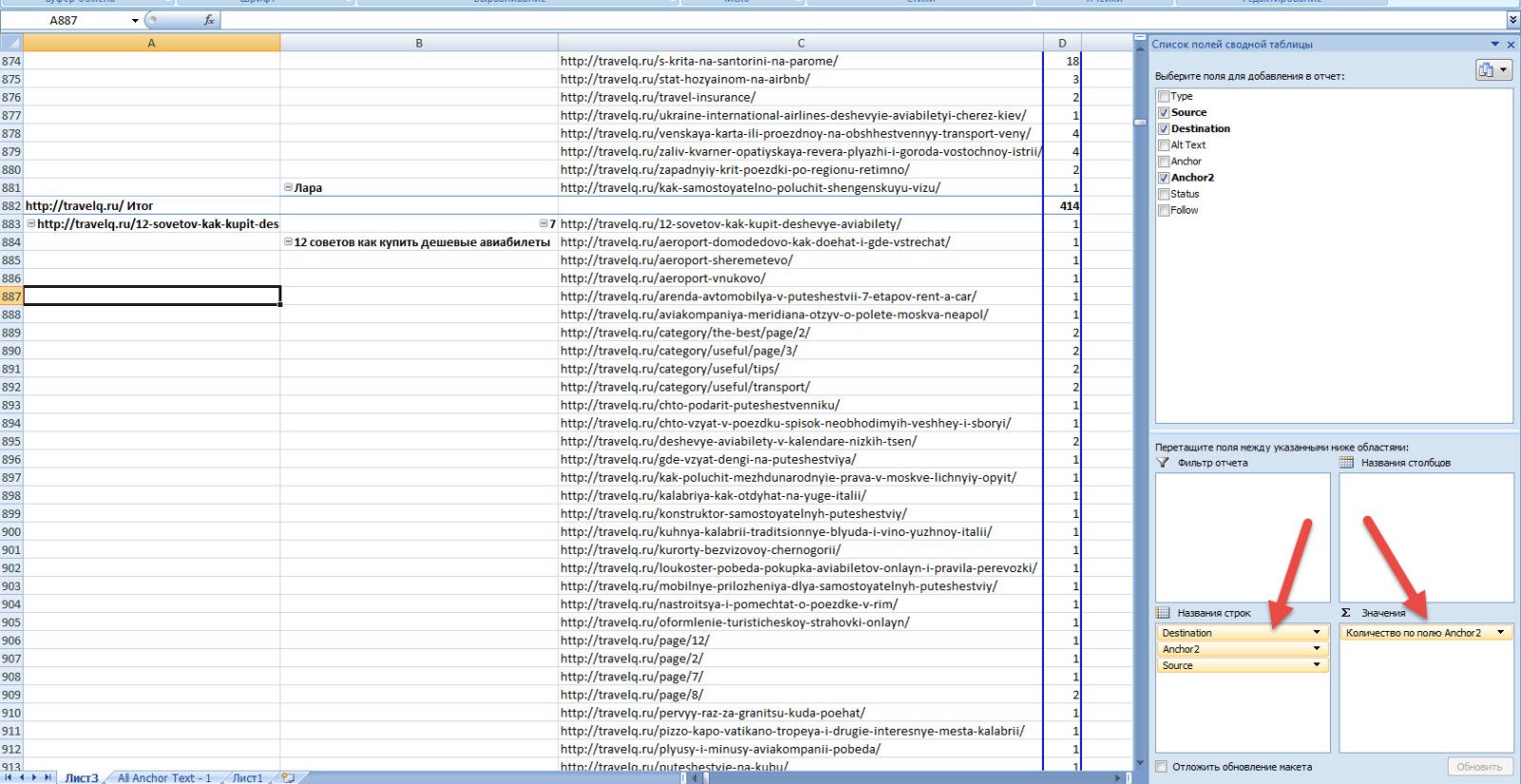
Таким образом, используя всю мощь сводных таблиц Экселя мы можем выстроить какую угодно структуру отчета по ссылкам.
В данном примере перелинковка, в основном, находится в меню второго уровня, которые генерируются динамически и выводятся на части страниц а не на всех, как главное меню. А представьте что перед вами сайт с 10 тыс. страниц, в котором перелинковка построена из контента с разными анкорами. Тут то и придет на помощь могучая SEO лягушка.
Экспериментируйте.
Ноя
2016
Об авторе:
DrMax. Занимаюсь аудитами, оценкой качества YMYL проектов и SEO сайтов более 20 лет. В настоящее время провожу аудиты и реанимирую трафик сайтов, восстанавливаю позиции в органической выдаче сайтов, помогаю снять алгоритмические и ручные штрафы Google. В портфолио - продвижение несколько десятков проектов как региональных частников, так и крупнейших мировых компаний. Владелец SEO блога Drmax.su. Автор 22 книг по продвижению и аудиту сайтов.